Artificial intelligence promises to transform medicine, science, and daily life. But every model trained, every prediction made, every convenience delivered is built on the most intimate currency of our age: personal data.
We have built the most sophisticated inference engines in history — and pointed them at ourselves.
I want to start out by saying I enjoy AI and feel that it is a growing and valuable tool. But there are reasons to be concerned. Here is a scary thought experiment! When you ask a voice assistant what the weather is tomorrow, you trigger a chain reaction invisible to the naked eye. Your voice is recorded, uploaded, analyzed, cross-referenced with your location history, and stored alongside millions of similar requests. The answer returns in seconds. What never returns — your data.
This is the foundational tension of the AI era: every meaningful capability depends on vast rivers of personal information flowing into systems we do not own, cannot fully inspect, and have only partially consented to feed. The question is no longer whether AI will reshape data privacy. It already has. The question is whether we will shape it back and whose ethics will define it.
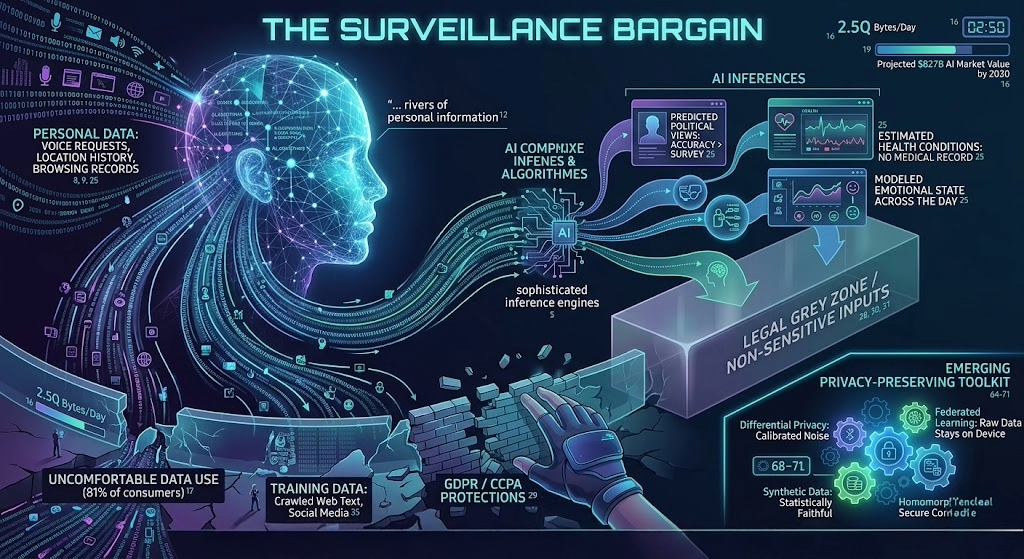
| 2.5Q – Bytes of data created every single day. Source: IDC / Statista | 81% – Of consumers say AI companies use data in ways they’re uncomfortable with. Source: Pew Research Center | $827B – Projected global AI market value by 2030. Source: Statista Market Insights |
The New Anatomy of a Privacy Risk
Traditional privacy threats were blunt instruments — a hacker stealing a password, an unscrupulous company selling an email list. AI has introduced something far more unsettling: the ability to infer what was never disclosed.
A large language model trained on your browsing history, purchase records, and location data can predict your political views with greater accuracy than a survey, estimate your health conditions without a single medical record, and model your emotional state across the day. This is not science fiction. It is the operational logic of recommendation systems, insurance algorithms, and hiring tools deployed right now.
The most dangerous privacy violation is not the one that steals what you know — it is the one that reveals what you don’t.
Inference-based privacy loss operates in a legal grey zone. Especially in the United States. When a company collects your data, regulations like GDPR (EU) or CCPA (California) offer at least nominal protection. When an AI system derives a sensitive attribute from non-sensitive inputs, the legal frameworks largely fall silent. Your medical data is protected. The fact that your shopping cart, sleep schedule, and social graph allow an algorithm to diagnose your condition — that is not.
The Training Data Problem
Every AI system that has impressed you was built on data produced by people — most of whom never knowingly consented to its use. The large language models powering today’s AI assistants were trained on crawled web text, books, code repositories, and social media posts spanning decades.
- Models can memorize and reproduce verbatim excerpts from their training data, including private information, credit card numbers, and medical records that appeared in training corpora.
- Federated learning and differential privacy offer partial mitigations, but implementation is inconsistent and often commercially disincentivized.
- The “right to erasure” under GDPR is nearly impossible to enforce for data woven into the weights of a trained model.
- Training data from marginalized communities is often overrepresented in harm-causing outputs while underrepresented in benefit-conferring capabilities. Just consider the socio-economic access to the systems that supplied the training data or where data (i.e., government and press) originated to train the large language models.
Surveillance Creep and the Normalization Effect
Perhaps the subtlest threat is not any single privacy violation but the gradual erosion of the expectation of privacy itself. Behavioral surveillance, once the domain of authoritarian states, is now the routine business model of consumer technology. AI has accelerated this normalization dramatically, and society is either ignorant about it or cheering it on.
When a fitness app reminds you to stand up, an emotion-detection system monitors employee productivity, or a smart home device notes your sleeping patterns, each data point seems innocuous. The AI systems aggregating and cross-referencing them are not. The whole is not merely greater than the sum of its parts — it is a different category of thing entirely.
| KEY TAKEAWAY Modern AI systems can combine innocuous data streams — step counts, typing speed, purchase timing, scroll behavior — to infer sensitive characteristics including mental health status, political orientation, and financial vulnerability. No single data point triggers consent or regulation. The inference does. |
The Regulatory Landscape Is Moving — But Not Fast Enough
Governments have not been entirely passive. The European Union’s AI Act establishes a risk-tiered regulatory framework that restricts certain high-risk AI applications in employment, credit scoring, and biometric identification. The United States has produced a patchwork of state-level regulations and executive orders that falls well short of comprehensive federal law. I am a small government advocate. The government rarely does anything good, but this issue may be too large and complicated to ignore.
What frameworks are getting right
Risk-based approaches that impose greater obligations on higher-stakes applications represent genuine progress. Data minimization requirements, algorithmic impact assessments, and prohibitions on real-time biometric surveillance in public spaces are meaningful constraints.
What they are missing
Current frameworks largely regulate the collection and use of data, not the inferences drawn from it. They focus on identifiable personal data rather than derived outputs that can be equally sensitive. They address individual systems rather than the ecosystem of data brokers, cloud providers, and API integrations through which modern AI products actually operate.
The Emerging Privacy-Preserving Toolkit
It would be wrong to suggest the technical community has been indifferent. There are dedicated certifications for professionals that are at the intersection of privacy and AI governance, i.e., IAPP’s Artificial Intelligence Governance Professional. A growing body of research and engineering practices offer genuine hope that AI capability and data privacy need not be permanently at war.
- Differential privacy injects carefully calibrated noise into training data so that no individual’s information can be reliably extracted from a trained model’s outputs.
- Federated learning keeps raw data on users’ devices, training models on decentralized data without centralizing it first.
- Synthetic data generation allows AI systems to be trained on statistically faithful but entirely artificial datasets that carry no individual-level privacy risks.
- Homomorphic encryption and secure multi-party computation allow computations to be performed on encrypted data without exposing it to the service provider.
Privacy-preserving AI is not a contradiction in terms. It is an engineering discipline that the industry has chronically underfunded because the business models built on data extraction have been extraordinarily profitable.
What Accountability Actually Requires
Technical solutions are necessary but insufficient. The deeper problem is that the institutions building and deploying AI systems face asymmetric incentives. Data collection and inference capabilities are enormously profitable. Privacy violations impose costs primarily on individuals who rarely have the information, resources, or legal standing to pursue remedies.
Rebalancing requires structural interventions: mandatory algorithmic audits with genuine independence; data protection by design requirements with enforcement; a meaningful private right of action for individuals harmed by AI systems; and international coordination on cross-border data flows.
| KEY TAKEAWAY. The most meaningful privacy protection is not a regulation or a technical control. It is a decision — made by companies, engineers, investors, and policymakers — about what kind of infrastructure is worth building, and at whose expense. |
The Choice Ahead
The trajectory of AI and data privacy is not fixed. History offers genuine examples of technology ecosystems reshaped by public demand, regulatory intervention, and shifts in professional norms — led fuel phased out, seat belts mandated, financial disclosures required.
The surveillance bargain is not a law of nature. It is a set of choices — about architecture, incentives, enforcement, and values — that can be made differently. The costs of making them differently are real. The costs of not doing so are being borne, invisibly and unequally, by everyone whose data powers the systems they never built and cannot stop.
As an attorney, certified data privacy professional, and regulatory compliance practitioner, I want AI to succeed. But I want it to succeed ethically. We built the most sophisticated inference engines in history and pointed them at ourselves. The next question is whether we will apply even a fraction of that sophistication to the problem of governing them.
